
Informatika pro kombinované lyceum/2015/Filip Vosáhlo
| střední škola | |
| Příslušnost: Filip Vosáhlo | |
Toto je stránka vytvořená v rámci již proběhlého kurzu a nyní sloužící k jeho archivaci. Tuto stránku již prosím needitujte! Pokud se chcete do kurzu zapojit, pak vyhledejte aktuální běh na hlavní stránce kurzu či se zeptejte v příslušné diskusi.
Tohle je stránka, kam si Filip Vosáhlo zapisuje poznámky z hodin informatiky. Zatím je tu cosi o tom, co je počítač vlastně zač, o tom, jak jej sestavit, o programovatelnosti, ukládání informace, zobrazování informace, pár věcí o druzích programů a souborů a mnoho dalšího zajímavého (račte nahlédnout do obsahu).
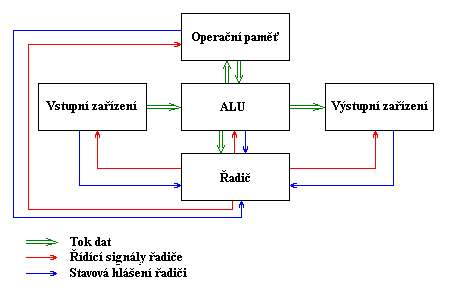
Co je počítač vlastně zač?
[editovat]Kybernetické schéma počítače
[editovat]
Kdyby vám nestačil obrázek, podívejte se, co o tom, co jsme probírali, píšou na Wikipedii. Nebo se taky můžete podívat na úplně jiný obrázek. Máme různé druhy zařízení; jejich příklady budiž uvedeny v této tabulce:
{kind=link}
| vstupní zařízení | procesor | paměť | výstupní zařízení |
|---|---|---|---|
| klávesnice, myš, mikrofon, scanner, joystick (více zde) | pevný disk, grafická, zvuková karta, řadič (více zde) | RAM (operační paměť), pevný disk, flash disky... | obrazovka, reproduktory, tiskárna, sluchátka (více zde) |
Vývoj výpočetní techniky
[editovat]Jak uchovat informace? Jak napsat pracovní postup? Dnes nemáme problém cokoli zapsat písmem, to ovšem nebyla vždy samozřejmost.

Nejstarším dochovaným „záznamem“ je nástěnná jeskynní malba (nástěnné malby buvolů jsou staré přibližně 30 000 let). (Těžko říci, pod jakou záminkou si pračlověk buvoly v jeskyni maloval – možná i za účelem rozličných magických úkonů, spíše ale prostě proto, jelikož měl potřebu buvola někde zaznačit.) Postupně se přechází od malůvek a maleb k symbolům – kráva na značce už neznamená krávu, ale prostě něco obecného (symboly jsou něco dohodnutého a jejich význam nemusí být zřejmý na první pohled – člověk se je většinou musí nejprve naučit). Ještě abstraktnější jsou písmena – vyvinula se z prastarých symbolů, které vzešly ze zjednodušených obrázků. Písmena jsou symboly, jejichž význam se musí naučit všichni – tří písmena obsažená v napsané podobě slova „sto“ nemají se stem nic společného, zapsaná podoba slova „žár“ rozhodně nevyjadřuje horkost žáru, o „stožáru“ už ani nemluvě.
Postupujeme tedy pozvolna od obrazů (pradávno), přes značky (původně například označení vlastnictví), k písmu (které se, vzato kolem a kolem, objevilo vlastně docela nedávno).
Vývoj záznamu pracovního postupu
[editovat]Abychom si mohli nějaký návod předat skrze slova či písmo, musíme hovořit týmž jazykem a musíme navzájem rozumět jednotlivým užitým pojmům (kdo neví, co přesně má rozumět pod pojmem ulice, tomu asi těžko pan profesor vysvětlí, jak se dostane k němu domů). I takový pracovní postup může mít však mnoho podob; před páně profesorovy dveře se můžeme dostat buď díky obyčejnému pracovnímu postupu (zahněte doleva, doprava, jděte rovně...), prostřednictvím vojenských povelů (pochodem v chod, vlevo v bok...) nebo soustavou souřadnic, bodů, přes které máme projít. Postupujeme tedy od vysvětlení před povel ke vzorci (stejně jako od obrazu přes značku k písmu) – tomu říkáme formalizace.
Jak převést něco do digitální podoby?
[editovat]Vše musí mít číslo – všechny znaky tedy musíme očíslovat. Aby bylo jasné, kde který znak končí a kde který začíná, musí být všechny složeny ze stejného množství číslic („C“ tedy nemůže být 3, ale 003, atd.). Deset cifer by ovšem bylo příliš mnoho (deset cifer = deset různých stavů součástky), proto tedy užíváme pouze dvojkovou soustavu (0, 1, 10, 11, 100...).
Zpětná vazba
[editovat]
Je nutno, aby byl počítač schopen reagovat na podněty z okolí a neběžel nezávisle; podobně jako robot při našem pokusu koukal, jestli do něčeho nenarazil, počítač by měl změnit běh programu, když klikneme myší. Jednou z nejjednodušších zpětných vazeb je plovákové splachovadlo (když není nádrž plná vody, plovák je dole a vodu dovnitř pouští). Zpětná vazba je vlastně schopnost sledovat, co se v okolí děje, a na základě toho adekvátně upravovat svoji vlastní činnost (splachovadlo musí napouštět vodu právě a jen ve chvíli, kdy v nádrži není; pokud by spustilo proud vody i při plné nádrží, vytopili bychom sousedy).
Program
[editovat]Program je posloupnost instrukcí, která počítači říká, jak má tu kterou úlohu vyřešit; program je pracovní postup zapsaný tak, aby mu počítač rozuměl. Programu, který právě probíhá, říkáme proces. Algoritmus je oproti tomu přesný návod, jak jednu danou operaci vyřešit, který se skládá z konečného počtu kroků.
Jak sestavit počítač?
[editovat]Splachovadlo ovládá proudem vody proud vody a je tak velice jednoduše schopno zpětné vazby, což je princip, který potřebujeme. Elektromagnetické relé funguje úplně stejně, jako zmiňované splachovadlo, jen s proudem elektrickým (dnes ho nalezneme zejména ve starých domovních zvoncích). Z elektromagnetických relé už lze sestavit počítač (ač hodně velký a poruchový).

Dalším nablížením k něčemu, co potřebujeme, je elektronka. Elektronka se dosud užívá v dobrých zesilovačích. Je výkonnější a menší než relé; mezi dvěma nespojenými póly vzniká proud díky tomu, že se pustí elektřina do drátku mezi nimi – pak přeskakuje. Když v drátku proud není, elektronka je nečinná.
Tranzistor (viz zde) funguje velmi podobně, jen všechny tajemné čachry provádí na základě vodičů a nevodičů (součástka tak nemusí být ve vakuu ve skleněné baňce). Integrovaný obvod (užívaný široce v počítačích, rádiích, televizích a podobných záležitostech) je vlastně pouze velké množství tranzistorů, jež jsou nacpány do jednoho čipu. Dnes už nemáme v počítačích přímo tranzistory, ale různé vrstvičky vodičů, které se překrývají – fungují ale úplně stejně.
Logické obvody
[editovat]Tranzistor má dva póly, mezi kterými obyčejné proud neprochází. Proud jím prochází pouze tehdy, pokud do prostředního, třetího pólu pustím proud. Proud, který tranzistorem projde (pokud může), se uzemní. Pokud proud tranzistorem nemůže procházet, odchází vedlejším vývodem, kde způsobí, že součástka na vedlejším vývodu naměří 1. Prostřední vstup tedy buď nepouští proud (0) a poté vedlejší vývod naměří 1, nebo proud pouští (1) a vedlejší vývod tedy naměří 0. Pokud je tedy vstup na 0, je výstup na 1 a obráceně. Tranzistory mohu zapojit i dva za sebou. Dvojitý tranzistor je součástka, která dokáže pracovat se dvěma vstupy; vždy na něm naměříme 1, nulu jen tehdy, když jsou oba vstupy zapnuté (1) – pro toto se užívá označení NAND. Zkombinujeme-li jednoduchý tranzistor a tento dvojitý, dostaneme AND: ten dává přesně opačné výstupy, než NAND, jelikož nejprve použijeme NAND a pak zapojíme jednoduchý tranzistor, které výsledek obrátí. Dvanáct tranzistorů již stačí na to, abychom dokázal sestrojit jednoduchý stroj, který dokáže sčítat čísla ve dvojkové soustavě (polosčítačka). Úplná sčítačka dokáže již provádět posuny řádů (na to, pokud bychom si vystačili s prvními pár desítkami, by stačilo 32 splachovadel). Tomu, aby takovéto sčítačky fungovaly, slouží různá jednoduchá hradla (různě sestavené soustavy tranzistorů). Jedním z nich je tzv. OR (to posílá dál nulu, jen pokud jsou oba výstupy vynuty, jakmile alespoň jeden ze vstupů dává 1, posílá dál rovněž 1), dalším je NOR (ten funguje přesně obráceně, než jeho o N ochuzený kamarád). Jedním z nejvíce ceněných -ORů je ovšem XOR, tedy tzv. exkluzivní logický součet – dostane-li dvě nuly, dá rovněž nulu, a nulu vyhodí také v případě, dostane-li dvě jedničky; naopak jedničku lze od XORa dostat jen tehdy, je-li jedním ze vstupů jednička a druhým nula.
A to je vlastně vše, co potřebujeme – jakmile už dokážeme sčítat celá čísla, dokážeme je zanedlouho i porovnávat, odesílat kamsi do paměti a tak všelijak podobně.
Programovatelnost
[editovat]Programovatelnost je schopnost stroje činit něco podle předem dané posloupnosti instrukcí.
Na staré egyptské desce se v hieroglyfech píše, co všechno má člověk udělat, až umře, aby se dostal do nebe (obsahuje rady typu „třetímu strážci řekni, že jsi nesmilnil s hospodářskými zvířaty“ a podobně). Jedná se o egyptskou Knihu mrtvých – je to návod, jak se dostat do nebe, soustava rad, soustava návodů k použití, soustava algoritmů – takových máme ze starověku málo, nicméně evidentně už tehdy byly pokusy zaznamenat pro někoho návod, jak něco přesně provést.
Filon Byzantský sestrojil stroj na mytí rukou, který stál na ulicích; zákazník do stroje vhodil minci správné hmotnosti, díky té vypadla z jedné roury kulička mýdla, ta dopadla na ručičku, která se jako kukačka z hodin vysunula na zákazníka. Ten si vzal kuličku, tím však odlehčil ručičku, díky čemuž začala téci voda; ta se ovšem po čase zastavila (za tím účelem byla poháněna speciálním převodem). Zákazník si tedy umyl ruce a šel dál. Toto byl vlastně jeden z prvních počítačů, ačkoli byl velmi jednostranný (dnes bychom řekli, že se jednalo o automat – automaty (ačkoli značně univerzálními) jsou ale i naše dnešní počítače). Tyto automaty na mytí rukou se ale vůbec neuchytily (nikoli kvůli tomu, že by lidé jednoduchý automat obelhávali, ale kvůli tomu, že sestavení a udržovaní stroje v chodu bylo výrazně dražší, než si najmout otroka se džberem vody, ručníkem a mýdlem).

Automatické tkalcovské stavy – dříve byla obrovská práce utkat nějaký kus látky. S průmyslovou revolucí sice oblečení zlevnilo, stále ovšem bylo velkou otázkou, jak přimět stroj, aby utkal nějaký přesný vzor. Jacquardův stroj to nakonec dokázal díky děrným štítkům, skrze které propadávaly či nepropadávaly tyčky s nitěmi; automaticky tkal rozličné vzory. Toto byl vlastně jeden z prvních programovatelných strojů – stroj dokázal utkat naprosto jakýkoli vzor, pokud mu dodali správnou soustavu děrných štítků.
Spojení prvků
[editovat]Všechny prvky, o kterých jsme dosud hovořili (digitálnost, programovatelnost, zpětná vazba), jsou sice bezesporu užitečné, nicméně my potřebujeme stroj, který by toto všechno dokázal najednou; potřebujeme digitální programovatelný stroj se zpětnou vazbou. Pan Babbage se do toho pustil jako první a sestrojil první „digitální“ kalkutačku.
.jpg)
Konrad Zuse sestavil ve svém berlínském bytě první skutečně funkční počítač – jmenoval se Z1 a byl elektromechanický (používal v něm relé a kolíčkovou paměť – paměť pomocí vysouvacích a zasouvacích kolíčků) – uměl řešit i složité algebraické výrazy. První verze vzala za své při bombardování, nicméně pan Zuse se nevzdával.
Počítač Z2 se moc nepovedl, Z3 už byl ovšem čistě elektrický bez mechanických prvků (ze součástek staré telefonní ústředny) a pomocí jednoduchého programovacího jazyka dokázal řešit rozličné matematické operace.
Další pokus, počítač Z4, vznikl po válce; vyrůstal ve vzduchotěsných skříních a měl už dokonce tiskový výstup. Užíval se k vypočítávání mezd a dávek v podnicích a podobným početním úkonům.
Od Zuseho ovšem prvenství v počítačové sféře přebrali Američané; sestrojili nejprve ENIAC (stalo se to roku 1945 a byl to první elektronkový počítač). V roce 1954 postavili první polovodičový počítač TRADIC, roku 1971 v Americe vznikl první integrovaný procesor, roku 1975 pak první osobní počítač s čipem Intel 8080.
Od té doby už se počítače prakticky neliší – jsou sice stále menší, levnější a výkonnější, ale v podstatě stále tytéž, fungující na stejném principu.
Ukládání informace
[editovat]Informace lze ve dvojkové soustavě ukládat velmi jednoduše; buď uložíme nulu, nebo jedničku. Dvojkovou soustavu lze nalézt třeba v kelímcích: buď je kelímek otočen vzhůru nohama a je nepoužitý (0), nebo stojí dnem dolů a to znamená, že už z něj někdo pil (1). O něco digitálnější je Jarquardův šicí stroj; tam nalezneme děrné destičky, ve kterých buď na určitém místě dírka je (1) nebo není (0).
Na stejném principu vlastně fungují i děrné štítky (na kterých se ještě nedávno programovalo) nebo Babbageho děrná páska.

Stejné jsou i magnetické pásky; každý jeden určitý maličký kousek pásky je zmagnetizován buď na jednu, nebo na druhou stranu. Diskety už jsou jen vylepšením – informace na ně lze zapisovat výrazně hustěji a jelikož je kulatá, můžeme se čtením začít z kteréhokoli místa a nemusíme postupovat od začátku. Pevný disk ukrývá je vlastně uzavřenou disketou, která se rovněž porůznu přehrává, jen se toho na ni vejde ještě mnohem víc, je novější a rychlejší.
Operační paměť
[editovat]Kdyby se měly všechny informace, mezivýpočty a procesy zapisovat na disk, trvala by každá operace řádově tisíckrát déle. Proto se začala používat operační paměť – tedy taková paměť, která slouží jen chvíli, a jakmile je počítač vypnut, všechno zapomene. Jako první k tomuto účelu použili Američané takzvanou Williamsova katodová trubice, kterážto fungovala na principu elektrického paprsku, ovládaného magnety (takto týraný paprsek stále dokola jezdí po hraně baňky a neustále obnovuje, kde je nula a jednička). Totožná trubice se začala nedlouho poté užívat i u televizí.

Dalším krokem byla feritová paměť založená na magnetizování feritových jader.
Dnešní operační paměti fungují velice podobně; tranzistor proud drží nebo nedrží (nula nebo jedna) a my tuto informaci můžeme přečíst; tím ji ovšem zničíme, takže ji musíme zapsat znovu (jakmile se počítač vypne, ze všeho se ale stejně stanou nuly, napětí zmizí).
Flashová paměť
[editovat]Oceníme však i polovodičovou paměť, která si něco pamatuje, i když počítač vypneme. Takováto paměť funguje na principu směsi (vrstviček) dvou chemických látek, které udrží chemický náboj, jež do nich pustíme. Tomu říkáme flashová paměť.
Zobrazování informace
[editovat]Informaci můžeme zobrazit třeba na pragotronu – na dvou rozevřených kartičkách je vždy jeden znak, který se musí s klapotem nalistovat. Tohle je mechanické zobrazování informace; nemohu zobrazit naprosto cokoli, ale jenom takový znak (nebo soustavu znaků), kterou mám na kartičkách připravenou.
.jpg)
Ve dvojkové soustavě (i když stále mechanicky) funguje například i odjezdový panel na Hradčanské – „plíšky“ mají dvě různé barvy a jsou schopny libovolné kombinace; kdybychom panel správně naprogramovali, byl by schopen zobrazit i obrázek.
Digitron je už digitální, ale má velmi omezenou znakovou sadu (dá se užít nanejvýš tak k jednoduchému odpočítávání).

CRT obrazovka
[editovat]CRT obrazovka oproti tomu funguje na principu Williamsovy katodové trubice. Za pomoci běhajícího paprsku (který dvacet pětkrát za vteřinu oblétne a obnoví všechny body, které má ve svém poli působnosti) už zobrazím vlastně cokoli. Podle toho, jak je paprsek v kterém bodě intenzivní, vnímáme jeho světlost (paprsek je ale jen jednoho druhu, jedná se tedy stále o obrazovku černobílou).

Barevná televize funguje velmi podobně – je zde stále jen jeden paprsek, nedopadá ovšem rovnou na „obrazovku“, ale na škálu zelených, modrých a červených „průsvitů“, které jsou těsně vedle sebe (týž paprsek tedy na obrazovku v různých zlomcích sekund promítá buď modré, zelené nebo červené světlo, a jelikož jsou všechny body těsně vedle sebe, v oku si je propojujeme v jeden obraz). Tyto tři barvy jsou obrazovce užity proto, jelikož odpovídají barevnému schématu našich čípků v oku.
Jak je to vlastně s barvami?
[editovat]Při promítání si nesmíme plést míchání barev výtvarných a míchání barev fyzikálních. Zatímco když všechny základní tempery (zelenou, modrou, červenou) smíchám dohromady, vyjde mi černá, pokud přes sebe promítám zelené, červené a modré světlo dostanu bílou (má to svou logiku – při promítání se jedná o světlo, kterého je víc a víc a je tudíž světlejší, u temper jde o hmotu).
Na ještě jiném principu funguje LCD obrazovka. V ní jsou těsně vedle sebe jsou naskládány vždy tři tekuté krystaly tří základních barev; každý z nich svítí, jde-li do něj proud. Jednotlivé světelné obdélníčky můžeme na obrazovce rozeznat i prostým okem.
Zamyšlení
[editovat]Je vlastně zajímavé, že v malinkatém flashdisku je ukryto na sto třicet miliard jednotlivých tranzistorů s propalovacími vrstvičkami, které si pamatují nulu nebo jedničku.
Druhy programů
[editovat]Jako první se v počítači spustí zpravidla spustí program zvaný BIOS. BIOS je takzvaný zaváděcí program, který je přímo na základním hlavním čipu počítače. Když se zapne, zkontroluje, zda je počítač celý a zda fungují všechna spojení, která fungovat mají, a podle stanoveného pořadí zkontroluje různá úložná místa a poohlédne se, zda na nich není operační systém. Je-li v počítači jen jeden (nejčastějším je Windows), předá mu přímo slovo, máme-li jich více, zpravidla se mezi BIOSem a operačním systémem dostane ještě ke slovu program, který dá uživateli na výběr mezi různými druhy operačních systémů.
_in_a_Winbond_W39V040APZ-5491.jpg)
Operační systém
[editovat]Operační systém se skládá z jádra („kernel“), které běží pořád. Takovéto jádro umí ty nejzákladnější dovednosti, které od počítače čekáme, tedy spustit program, překopírovat soubor a tak podobně. Dále se pod operační systém řadí programy systémů. Tyto programy si operační systém spouští sám podle toho, kdy je potřebuje, a jsou to programy, které dokáží například komunikovat s novým flashdiskem nebo instalovat aktualizace. Nakonec zde máme spoustu systémových nástrojů, což jsou (konečně) programy, které si uživatel spouští sám, když je potřebuje – například Průzkumník Windows.
Uživatelské aplikace
[editovat]Nesmíme ovšem opomenout ani uživatelské aplikace. Těch je rovněž několik druhů – rozlišujeme jednak takové aplikace, které nám umožňují pouze si některá svá data prohlédnout (tedy přehrávače audia, videa a dalších rozličných věcí) a takové aplikace, které nám umožňují vlastní data upravovat (tedy editory všeho možného – textu, zvuku, videa). U obou aplikací je předpokladem, že již nějaká data máme (bez dat, ať už bychom si je chtěli pouze prohlédnout, či je upravit, by nám tyto programy byly k ničemu). V neposlední řadě máme však ještě komunikační programy, tedy především internetové prohlížeče, která užíváme za účelem sdílení dat (prostřednictvím internetového prohlížeče se snažíme nějaká data přijmout a nějaká zase odeslat). Ani zde se tedy bez vlastních dat či souborů neobejdeme.
Druhy souborů
[editovat]Soubor je množina dat. Rozlišujeme na jedné straně například obrázky, texty, zvuky či videa (s rozličnými příponami), na straně druhé pak systémové soubory (většinou s příponami .exe, .ini, .bat či v Linuxech bez přípony), základní programové knihovny (s příponou .dll – tyto knihovny obsahují souhrny těch nejzákladnějších pokynů jako zavři okno, otevři okno, posuň okno, spusť v okně program a tak podobně a jsou otevřeny všem ostatním programům, kteréžto do nich mají přístup a tyto pokyny si z nich berou, což jest praktické, neboť se ty nejjednodušší věci nemusí v každém programu programovat znovu a znovu) a konfigurační soubory (tedy soubory, do kterých si ostatní programy ukládají, jak jsou nastavené).
První jmenovaná množina dat (tedy texty, zvuky, obrázky či videa) není pro samotný chod počítače vůbec důležitá. Jejich ztráta sice může mít vliv na duševní zdraví uživatelovo, ovšem chod počítače nikterak neohrozí. Toto jsou totiž soubory, se kterými má teprve počítač nějak pracovat a případně je přetvářet – jsou to uživatelské soubory.
Druhá skupina souborů je ovšem mnohem důležitější – programy, základní programové knihovny a konfigurační programy totiž počítači sdělují, jak má s daty pracovat. Pokud se tedy tyto soubory poškodí či vymažou, počítač vlastně neví, co má dělat. (Takzvané samoobslužné viry založené na lidské hlouposti fungují na tom principu, že si důvěřivý uživatel sám smaže některý z důležitých systémových souborů – fungování počítače tím pochopitelně nezlepší, ba naopak.)
Zástupci, které občas na ploše, jakož i jinde v počítači potkáme, žádnými soubory nejsou – jsou pouze odkazy, kde na disku ten onen požadovaný program nalezneme.
Neméně důležitou věcí jsou pak složky. Složka samotná ovšem není žádným šanonem, ve kterém by bylo přímo uvnitř uloženo odpovídající množství dat. Složka je opět pouze seznam, kde na disku najít ten který soubor, který je do ní zařazen (i přesto jsou ale takové složky v počítači velmi důležité a pomáhají nám udržovat pořádek).
Jak od sebe odlišit soubory?
[editovat]O jaký soubor jde, poznám podle jeho jména, podle toho, jak jsem jej pojmenoval. Když se však chceme přesvědčit, o jaký druh souboru jde, musíme hledět na příponu – přípona nám řekne, zda je dotyčný soubor obrázkem, textovým souborem, videem či něčím ještě úplně jiným.
Problém nevzniká, pokud soubory prostě otevíráme a zavíráme, na polízanici si ovšem někteří uživatelé zadělávají, pokud chtějí typ souboru změnit. Ten se totiž nezmění, pokud ručně změním příponu (chci-li z formátu MP4 učinit AVI, nestačí mi, že přípony za názvem souboru zaměním, tím totiž docílím leda tak toho, že počítač bude mít obtíže s jeho otevřením; soubor musím za pomoci nějakéh šikovného programu převést z jednoho formátu do druhého).
Jaké známe přípony?
[editovat]| obrázkové soubory | audia | videa | textové soubory | tabulkové soubory | prezentace |
|---|---|---|---|---|---|
| JPEG/JPG (využívají ztrátovou kompresi, obrázek se zjednodušuje, ale tak, aby to naše oko nepoznalo), PNG (nezatíženo žádnou licencí), GIF (animace a takové věci), zvektorizované obrázky (neukládá se jako pixely, ale jako čáry, které při přiblížení nezrní – formáty AI, SVG, EPS). | AU, WAW, MP3 | AVI, MP4, MPG, MPEG | TTXT, ODT, DOC, DOCX | XLS, XLSX, ODS | PPT, PPTX, ODP |
Mezi vlastnosti souboru patří i práva k němu – kdo ho smí upravovat, kdo pouze číst, kdo ho nemůže otevřít vůbec.
K tématu doporučuji wikipedistické články o textových procesorech, vektorové grafice, tabulkových editorech či prezentačních programech.
Velikost souboru
[editovat]Nejmenší bývají textové soubory, tisíckrát větší jsou obyčejně obrázky a tisíckrát větší místo než obrázky v paměti zabírají videa.
Velikost souborů se určuje v bitech – b. Bit je jedna jednička nebo nula (jeden bit = 1 nebo 0). (Z anglického bit – kousíček.)
Následují byty – B (byte – bajt). Jeden bajt (byte) je osm bitů, můžeme s ním tedy zapsat dvě na osmou kombinací (256 věcí – tím už lze obsáhnout třeba jednu znakovou sadu).
Tisíc bytů je jeden kilobyt – Kb. V praxi je ovšem mnohem pohodlnější rozdělovat bajty nikoli po tisících, ale po tisících dvacet čtyřech kusech (neboť 1024 je mocnina dvojky). Proto se užívá spíše této míry, které se říká kibibajt – KiB (1KiB = 1024B).
Po „kilu“ následují předpony „mega“, „giga“ a „tera“ – princip zůstává stejný, jen se vše násobí. Pro snazší uchopení převodů jednotek doporučuji prohlédnutí této wikipedistické tabulky.

Textové soubory
[editovat]Prostý text
[editovat]Prvním druhem textových souborů je prostý text (např. s příponami .exe či .asc). Principem prostého textu je, že přesně totéž co v něm napíšu a uložím, se ve stejné podobě uloží i do paměti (slovo „HESLO“ zapsané v prostém textu se jako „HESLO“ uloží i na disk). Prostý text jednoduše otevřeme například Poznámkovým blokem. V prostém textu jsou často ukládány i kódy programů s rozličnými příponami.
Značkové formáty
[editovat]Dále známe značkové formáty (s příponami .rtf nebo .tex). Text, jenž je v tomto formátu, je na disku uložen takový, jaký skutečně je („HESLO“ je na disku opět „HESLEM“), ale je prokládán různými formátovacími značkami, které vypovídají o tom, kde začíná a končí ostavec, zda je text tučný či kurzívou a o mnohém dalším. Mezi značkové soubory patří i HTML, v kterémžto programovacím jazyku jsou napsané některé webové stránky.
<p>Text napsaný ve značkovém formátu může být <b>tučně</b>, <i>kurzívou</i> nebo třeba <u>podtrženě</u>.</p>
Aplikační formáty
[editovat]A nakonec jsou zde aplikační formáty (.doc, .docx, .odt). Texty v tomto formátu jsou uloženy jako velmi složité a zdánlivě nesmyslné hromady znaků a není počítáno s tím, že by jim kdo měl rozumět. Tento formát textu musíme otevřít správným editorem (Wordem, LibreOfficem), jinak z něj nebudeme nijak moudří (uvidíme pouze nesmyslná uskupení znaků). Textové editory si ovšem se změtí zdánlivých nesmyslů dokáží poradit a rozkódovat je do podoby, se kterou se dá pohodlně pracovat. Sofistikovanějším textovým editorům (tedy nikoli Poznámkovému bloku, ale třeba již zmíněnému LibreOfficu nebo Wordu) se říká textové procesory.

tomu, abychom si hezky ukázali, k
čemu slouží nezlomitelná mezera. Všichni určitě uznáte, že s nezlomitelnou mezerou to vypadá mnohem lépe.
Doporučuji se podívat na článkek o prostém textu, značkovacím jazyku, aplikačním softwaru, Wordu, LibreOfficu, poznámkovém bloku nebo textovém procesoru.
Typografie
[editovat]Po interpunkčních znaméncích, například po tečce, čárce, středníku, dvojtečce, vykřičníku či otazníku, píšeme mezeru – je to důležité nejen kvůli dobrému estetickému zážitku, ale například i kvůli správnému zalamování slov. Mezeru píšeme i zvenčí okolo závorek a uvozovek, ovšem nikoli uvnitř (tedy „takhle“).
Uvozovky nepoužíváme "takovéhle", ani „takovéhle”, ani «takovéhle», ani »takovéhle«, ale jen a pouze „klasické české uvozovky“.
Chceme-li napsat pomlčku, rozhodně nenapíšeme spojovník (-), ale skutečně pomlčku (–) nebo dlouhou pomlčku (—).
Rozněž si dáváme pozor na mezery — 4 m („čtyři metry“) rozhodně není totéž jako 4m („čtyřmetrový“).
Nejsme-li si jistí, obrátíme se na nějakou moudrou webovou stránku — třeba na příručku, kterou sestavuje Ústav pro jazyk český, nebo na stránku „Typomil“.
Jak napsat něco, co má hlavu a patu
[editovat]Než napíšeme první větu a pustíme se do samotného psaní, musíme mít jasno v tom, co bude hlavní myšlenka textu, co jím chceme sdělit, abychom jen prázdně neplkali. Samotná hlavní myšlenka bude však ve výsledné kompozici našeho pojednání až na třetím místě. Teprve když v ní máme jasno, můžeme se vrhnout na úvod.
Úvodem bychom měli čtenáře vtáhnout do obrazu — v prvních větách můžeme vyslovit něco šokujícího, čím si čtenáře či posluchače získáme, pokračovat můžeme nějakou obecnou pravdou či vlastní zkušeností, týkající se alespoň okrajově naší hlavní myšlenky. To vše proto, aby byl po úvodu čtenář navnazen na to, co přijde, a zároveň tušil, o co mi vlastně půjde.
Pokračovat lze pojmovou přípravou — musíme čtenáře připravit na to co přijde, zajistit, aby se orientoval v pojmech, které budu používat, aby měl základní vědomosti v oboru, kterému se budu věnovat, zkrátka aby měl veškeré předpoklady k tomu, že pochopí hlavní myšlenku.
Na již zmíněnou třetí pozici umístíme dobře rozmyšlenou hlavní myšlenku.
Po hlavní myšlence, kdy je čtenář naprosto ohromen, následuje upevnění — zde uvedeme příklady z aplikace naší hlavní myšlenky, zajímavosti, které z hlavní myšlenky vyplývají, příklady ze života, týkající se hlavní myšlenky, a tak podobně, aby čtenář viděl, že naše hlavní myšlenka skutečně stojí za to.
Na konci bychom měli vždy nalézt závěr — zde celé své pojednání shrneme, navodíme pocit, že je dobře, aby si čtenář ještě jednou zopakoval, co se vlastně dozvěděl, a měl dojem, že mu to celé k něčemu bylo.
Dodržíme-li těchto pět myšlenkových kroků, měl by náš text dávat alespoň základní smysl, o což nám přece jde.
Domácí úkol
[editovat]1. Y = 0, Z = 0 Vidíš řadu čísel? ANO > jdi k číslu nejvíce vlevo NE > Jdi k první číselné řadě vlevo nahoře a jdi na krok 4.
2. je tam číslo? ANO > přičti 1 k Y, přičti jeho hodnotu k Z, jdi o číslo doprava a opakuj krok 2. NE > vyděl Z Ypsilonem, výsledek ulož do X, jdi na levý kraj řady a pokračuj na krok 3
3. je tam číslo?
ANO > Je menší nebo rovno X?
ANO > Vezmi ho, polož ho na další řádek do nové řady vlevo, postup o číslo doprava a opakuj krok 3.
NE > Vezmi ho, polož ho na další řádek do nové řady vpravo, postup o číslo doprava a opakuj krok 3.
NE > Je Y menší nebo rovno 2?
ANO > Nech být všechna čísla, která jsi při posledním opakování celého cyklu třídil, posuň se o řadu vpravo a začni od kroku 1.
NE > Přesuň se k levé z hromádek, které jsi právě roztřídil a začni od kroku 1.
4. Vidíš řadu čísel, která není na úplně posledním řádku?
ANO > Aplikuj na ni krok 2 a jakmile v něm odpovíš „NE“, vrať se sem.
Platí Y = 1?
ANO > Posuň řadu na nový řádek úplně dole a zachovej její levopravé umístění. Posuň se o řadu doprava.
Je tam ještě řada?
ANO > Opakuj krok 4.
NE > Posuň se k řadě nejvíce vlevo na dalším řádku a opakuj krok 4.
NE > Posuň se o řadu doprava.
Je tam ještě řada?
ANO > Opakuj krok 4.
NE > Posuň se k řadě nejvíce vlevo na dalším řádku a opakuj krok 4.
NE > Skonči.
Prvky algoritmu
[editovat]Z čeho se skládá algoritmus? Algoritmus je složen ze dvou základních částí: jednak ze samotných instrukcí (záznamů pracovního postupu) a druhak z takzvaných datových struktur, kde se zaznamenávají (povětšinou průběžné) informace.
Instrukce
[editovat]Instrukce (záznamy pracovního postupu) mají šestero částí. Jsou jimi krok, složený příkaz, skok, podmíněný příkaz, cyklus a volání podprogramu.
Krokem (instrukcí, povelem, příkazem) se rozumí jednoduchý pokyn, co má počítač udělat (např. „Přičti jedničku.“).
Složený příkaz jest nazýván rovněž makroinstrukcí, soustavou kroků, funkcí nebo i podprogramem, když je tak mnou náležitě označen a pojmenován.
Skok je jednoduchý pokyn, kam se má počítač „přemístit“ — například „Jdi na krok 1“.
Podmíněným příkazem se rozumí větvení či rozcestí, jehož částí je nějaká podmínka — například „Je-li číslo větší než 1, jdi na krok 3, jinak pokračuj dál.“
Cyklus je jistý krok, který počítač provádí stále dokola, dokud není splněna podmínka, aby jej ukončil. Cyklus je dvojího druhu: jednak cyklus platící tzv. pro všechny prvky množiny (např. „Pro všechna čísla od 1 do 5 proveď…“), druhak takřečený cyklus s podmínkou (např. „Dokud je C větší než 0, dělej…“).
Volání podprogramu je zapsaný odkaz (příkaz), aby počítač provedl předem definovaný složený příkaz. Toto podprogramové volání, které oživuje patřičný složený příkaz, má opět dva druhy. Známe jednak volání nerekurzivní (běžné, lineární, sekvenční), kde je podprogram jen jednoduše osloven, druhak vedeme v patrnosti volání rekurzivní (stále se samo v sobě opakující). V rekurzivním případě může jít jak o to, že zavolaný podprogram P obsahuje jako svoji vlastní součást volání po podprogramu P, tak i o to, že zavolaný podprogram P obsahuje jako svoji součást volání po podprogramu Q a podprogram Q obsahuje jako svoji součást volání po podprogramu P — toto je pak nazýváno rekurzí nepřímou.
Datové struktury
[editovat]Z datových struktur algoritmu známe zatím dvě: takzvanou proměnnou (tedy chvilkovou, měnící se paměť, která si například za účelem porovnání několik okamžiků pamatuje nějaké číslo, jako například proměnné X, Y, Z v mém domácím úkolu výše), a konstantu, která má naopak stále stejnou hodnotu (buď číslo, nebo text, například chybové oznámení).
Mnoho chytrého o algoritmu vědí na Wikipedii.
Počítačové sítě
[editovat]Počítačová síť je propojení počítačů či jim podobných přístrojů. Toto spojení může být realizováno skrz dráty (třeba připojení tiskárny k počítači) i bezdrátově (tiskárna ve vedlejší místnosti). Ani tajuplný internet není vlastně ničím jiným, než velkou bezdrátovou počítačovou sítí.
Počítačové sítě dělíme na (poetická to označení) malé a velké (případně „místní“ a „vzdálené“). Podrobněji se sítě rozdělují následovně:

PAN
[editovat]Jedná se o osobní síť (personal area network), nejmenší rozeznávanou síť, kterou máme téměř každý okolo svého osobního počítače. Jedná se například o připojenou tiskárnu, scanner, mikrofon či reproduktory. K hackování na této síti prakticky nedochází (musel bych si počítač nahackovat sám, což nemívám ve zvyku). Informace, které posílám do kopírky, proto většinou nešifruji (nemám je před kým skrývat). Objem přenášených dat je malý (obrázky, zvuk), nedochází tedy k tomu, že bychom si stěžovali, že naše připojení k tiskárně je příliš pomalé. Pokud se něco rozbije (například pokud mi křeček překouše kabel), tiskárna nefunguje, dokud nezakoupím kabel nový (je pak zcela na mě, kdy do elektra dojdu, na tom, že tiskárna netiskne, totiž tratím zase pouze já).
LAN
[editovat]Jde o menší, lokální počítačovou síť (local area network). Tímto výrazem lze označit například počítačovou síť vznikající v bytě početnější rodiny (sdílená tiskárna, napojený fax, propojené disky), dalším příkladem LAN může být propojená soustava počítačů v počítačové učebně na Lyceu (mají propojené disky, společné připojení k internetu, kde se hlásí jako jedna IP adresa, sdílenou tiskárnu a tomu podobně). O lokálních počítačových sítích v podstatě platí to samé, co o sítích osobních popsaných výše. Možnost vzájemného hackování, krádeží dat a podobných nesmyslů je sice o něco větší, ale stále nepravděpodobná (představa, že by autor těchto poznámek hackoval účet svého spolužáka, který na informatice sedí vedle něj, je poněkud groteskní). Proto se ani zde posílaná data nešifrují. Pořízení nového kabelu je o něco složitější (paní Kolářová musí schválit výdaj, kabel se musí zafakturovat a tak dále), ale není problém žáka posadit k počítači vedlejšímu, vše je na domluvě. Rychlost vzájemného propojení je také naprosto vyhovující (obsah mého „disku“ ke mně skrz dráty proteče raz dva).
MAN
[editovat]Dalším mezistupněm je síť metropolitní (metropolitan area network). Tyto bývají realizovány například ve velkých firmách. Sledujeme zde postupné vyhraňování vlastností: některá data už mohou být pro bezpečnost šifrována, může se projevovat pomalé spojení, uživatelé si začínají být cizí a již se nelze tak snadno dohovořit v případě nutných oprav.

WAN
[editovat]Jde o síť největší — wide area network. Příkladem této sítě (bezdrátově realizované) jest internet. Uživatelé se navzájem vůbec neznají a tudíž si nedůvěřují, je zde velké množství podloudných hackrů, tudíž je nutno vše velmi vynalézavými způsoby šifrovat. Máme-li pomalé připojení k internetů, pocítíme to, nejen když si stahujeme gigový film. Závady (nefunkční komponenty sítě) se dají snadno obcházet, neb pavučina má obrovské rozměry, případně lze padlé počítače programovat na dálku.
Příklad fungování WAN lze dobře vidět třeba na přihlašování se do e-mailu: Od počítače Googlu si vyžádám logovací stránku, pošlu mu zpátky přihlašovací údaje, od mi pošle stránku s mými e-maily, já napíšu nový mejl a ten mu pošlu, a on si jej uloží do příslušné části paměti, kde text čeká, dokud se k podobné proceduře neodhodlá můj přítel — adresát. Vše pochopitelně probíhá za komplikovaného zašifrování a dlouhých bezpečnostních a kódovacích procedur.
O počítačových sítích, jakož i o PANu, LANu, MANu a WANu, vědí na Wikipedii mnoho zajímavého.
Komunikační protokol
[editovat]Aby si dva počítače vyměnily libovolná data, musí být mezi nimi zaveden takzvaný komunikační protokol. Jde v podstatě o něco podobného, jako protokol o chování před japonským císařem („když vstoupíš do místnosti, poklekni a třikrát zabuš hlavou o zem“). Počítače si zkrátka musí rozumět, chápat, jaký kód znamená co.
Komunikační protokol se skládá ze dvou částí — z formátu předávání dat (počítače se musí shodnout na tom, co je nula a co jednička, co rozumět pod kterým součíslím a podobně) a z příkazů (počítač by měl vědět, jak svému plechovému kamarádovi na druhém konci drátu sdělit, že mu něco pošle, a počítač na konci spojení by měl této výzvě porozumět).
Sféru, ve které řešíme, aby počítače stejně rozlišovaly jedničku a nulu, připadně kde se staráme, funguje-li spojení a jsou-li všechny kabely zastrčeny ve správných zdířkách, nazýváme fyzickou vrstvou počítačové sítě.

Spojová vrstva počítačové sítě
[editovat]Jakmile se od těchto základních starostí oprostíme a začne nás zajímat, jak přenést celý soubor, nacházíme se už ve spojové (linkové) vrstvě počítačové sítě. Soubory se v síti přenášejí v datových balíčcích (paketech, datagramech) — soubor se buď vejde do jednoho, nebo je rozstrkán do většího množství balíčků. Datový balíček obsahuje
- hlavičku (zkoušku spojení — nesmyslné číslo, znak, který neplatí a pouze ověřuje, že všechno funguje a může se posílat)
- délku (číslo vyjadřující, kolik jedniček a nul posílaný balíček má — slouží pro kontrolu)
- samotná přenášená data
- kontrolní součet (kterým se ověří, jestli vše došlo v pořádku — když souhlasí, stále nemůžeme tvrdit, že se soubor přenesl v pořádku, ale když nesouhlasí, víme jistě, že se tak nestalo)
Kromě toho, že si dva počítače dokáží předat soubor, spolu musí i v této sféře ještě dokázat předepsaným způsobem komunikovat (například si vždy při posílání balíčku vyměnit cosi jako rozhovor, z počítačové řeči přeložený zhruba jako: Počítač A: Posílám Počítač B: Posílej! Počítač A: Poslal jsem! Počítač B: Děkuji!). Nejrozšířenějším komunikačním protokolem, který toto vše (příkazy i formát předávání dat) zastřešuje, jest Ethernet.
Síťová vrstva počítačové sítě
[editovat]A kráčíme-li ještě dál, docházíme až k vrstvám, kde je počítačů propojeno více, třeba několik desítek — to nazýváme síťová vrstva počítačové sítě. Zde vyvstává problém, jak zařídit, aby se počítače domluvily, kterému počítači mají daný datový balíček poslat. A v tom spočívá jeden z největších triků síťové vrstvy. Všechny počítače zde totiž mají svá specifická čísla. Když tedy chce například počítač číslo 2 něco poslat počítači číslo 7, vyrobí si datový balíček, jak popsáno výše, a k tomu přidá nejdůležitější věc: adresu. Celý tento balíček pak zabalí ještě jednou a pošle nejbližšímu počítači, který je směrem k adresátovi. Nejbližší počítač si balíček rozbalí, zjistí, komu je určen, zase ho zabalí a pošle ho o kousíček dál správným směrem (podrobněji se zabývá pouze balíčky, které jsou mu podle adresy určeny).
Na této třetí úrovni musí mít každý počítač dvě věci: svoji adresu (číselný kód) a svůj adresář (soupis toho, kterým směrem má posílat balíčky kterým počítačům — koncové počítače mají jeden směr „VŠICHNI“, počítače na křižovatkách mají adresáře obsáhlejší).
I na internetu (nejznámější WAP síti) musí mít každý počítač svou adresu. Má ji každý počítač připojený k internetu — říká se jí internet protocol adress, tedy IP adresa. IP adresa tedy není nic jiného, než jméno mého počítače mezi ostatními počítači na internetu.
Kdo chce dále hloubat o komunikačním protokolu, Ethernetu, o fyzické, spojové či síťové vrstě počítačové sítě, IP adrese nebo o podobných věcech, jistě ocení Wikipedii.
IP adresa
[editovat]I na internetu (nejznámější WAP síti) musí mít každý počítač svou adresu. Má ji každý počítač připojený k internetu — říká se jí internet protocol adress, tedy IP adresa. IP adresa proto není nic jiného, než jméno mého počítače mezi ostatními počítači na internetu.
Jak vypadá IP adresa? Jedná se vždy o číselné kódy přerušované tečkami či dvojtečkami — vypadat mohou různě, žijeme totiž v době přechodu z internetového protokolu verze 4 na internetový protokol verze 6.
IP adresa verze 4
[editovat]IP adresa z IPv4 je čtyřbajtová — skládá se ze čtyř čísel 0-255 (vyšší číslo než 255 se v ní vyskytovat nesmí, aby se vešlo do jednoho bajtu), která jsou oddělena tečkami. Přikladem takové adresy může tedy být například 123.212.8.77.
Kombinací, jak může IP adresa čtvrté verze znít, není příliš mnoho — konkrétně existuje 232 možností seskládání jejích čísel. Některé adresy jsou navíc rezervovány (kupříkladu 0.0.0.0) a nemohou být přiděleny. Všechny adresy z verze 4 jsou proto nyní již prakticky rozebrány (z většiny je vlastní rozličné firmy, které je následně poskytují svým klientům — uživatelům).
IP adresa verze 6
[editovat]IP adresa z IPv6 je šestnáctibtová — pro lidské uživatele se převádí do šesnáckové soustavy (0123456789ABCDEF) a skládá se vždy z osmi čtyřčíslí oddělovaných dvojtečkami. Jako příklad lze uvést adresu 20C4:8000:3F42:5123:0000:1BAO:EF01:8002. Dosud je využívána jen menšinou přípojů připojených k internetu. Pro úplnost dodejme, že jedno či více po sobě jdoucích čtyřčíslí, která se skládají ze samých nul, lze při vypisování kódu zcela vynechat. A také stojí za pozornost že „G“ (ani žádné pokročilejší písmeno abecedy) už v adrese nenajdeme — jde o šestnáctkovou soustavu.
Z předchozího odstavce je zjevné, že každá adresa šesté verze internetového prokolu je tvořena sto dvaceti osmi bity — to znamená, že existuje 2128 možných kombinací. Vzhledem k tomu, jak obrovským číslem je sto dvacátá osmá mocnina dvojky, lze bez přehánění tvrdit, že IP adresy verze 6 v dohledné době rozhodně nedojdou.
Dynamická IP adresa
[editovat]Používá-li počítač stále stejnou adresu, kterou má v sobě uloženou (jako „svoji vlastní identitu“), je to statická IP adresa. Existuje ovšem i dynamická IP adresa. Počítač může dostat takovou adresu přiřazenou od protokolu DHCP („dynamic host configuration protocol“), používá ji během toho, co je přes tento protokol připojen (například na veřejné wi-fi síti), pak zase odejde, tuto adresu zapomene a protokol ji může přiřadit zase někomu jinému.
Wikipedisté jistě ocení odkaz na články o IP adrese, internetovém protokolu verze čtyři nebo šest nebo o protokolu DHCP.
Jména domén
[editovat]Abychom si nemuseli pamatovat šíleně dlouhé kódy, kterými jsou nazývány počítače, co v sobě mají webové stránky, existuje protokol DNS — domain name system. Každá stránka má nějaké číslo, jako lidé máme však raději smysluplná slova či zkratky, protokol DNS nám tedy převádí názvy do kódů.
Jde o to, že internetové adresy mají různé přípony (.cz, .net, .de, .org atd.). Každou tuto příponu („doménu prvního řádu“) spravuje jeden velký počítač a má v sobě adresář, který říká, který název přísluší kterému kódu ( — které počítačové IP adrese). Chceme-li se připojit npříklad ke stránce seznam.cz, náš počítač se nejdprve zeptá počítače, který spravuje „.cz“ domény, jakou má seznam.cz IP adresu, tu dostane a přes ní se ke kýžené stránce teprve připojí.
Obdobně rozeznáváme i domény druhého či třetího řádu — jsou to vždy poddomény o řád výš již existujících domén, například „.wz.cz“ nebo „.firma.wz.cz“.

Hle, co vědí na Wikipedii o protokolu DNS či o doménách prvního řádu!
Trasování na Internetu
[editovat]I když se připojuji ke stále stejné stránce (například k výpisu e-mailu), neznamená to, že signál (spojení) mezi mnou a centrálním počítačem Seznamu vede přes stále stejné počítače. Jak jsme si sami dokázali, trasy našeho připojení k počítači australské univerzity vedly každému docela jinudy, ač jsme se (jakožto spolužáci na hodině informatiky) o spojení s ním pokusili všichni najednou.
Toto si lze kdykoli vyzkoušet — stačí do příkazového řádku Windows zadat příkaz „ping“ a příslušnou IP adresu (tím zjistíme, zda počítač na podobné legrace odpovídá) a pak pokračovat příkazem „tracert“ a příslušnou IP adresou (zobrazí se nám výpis IP adres, přes které náš požadavek putoval; zopakujeme-li „tracert“ o chvíli později, některé z vypsaných adres se velmi pravděpodobně změní).
Transportní vrstva počítačové sítě
[editovat]Procesy jsou základním obyvatelstvem počítačů a především se nesmějí pomíchat. Počítač z internetu neustále přijímá spoustu balíčků: stahuji-li si film a do toho prohlížím e-mail, dostávám spousty balíčků za oběma účely. Aby mohl počítač „stahovat“ (přijímat) více věcí najednou, musí umět rozpoznat, který balíček je který, musí umět každý balíček přiřadit konkrétnímu procesu. Přesně tím se zabývá transportní vrstva počítačové sítě.
Když se vzdálené počítače přes internet spojují, často jim balíčky chodí přes rozličné počítače (trasování je vteřinu takové a za vteřinu může být zase jiné). Balíčky se proto mohou vzájemně předběhnout, dojít v jiném pořadí nebo se dokonce ztratit. Počítač musí umět potřebné balíčky správně uspořádat, rozlišit a rozpoznat jejich pořadí, rozeznat, jestli nejsou duplicitní či zda nějaký neschází, odlišit, na jakou „hromádku“ (k jakému procesu) patří.
Podle priorit rozdělujeme protokoly zabývající se touto problematikou na protokoly spolehlivé a nespolehlivé.

Spolehlivé protokoly
[editovat]Spolehlivé protokoly užíváme například když stahujeme film. Dohlíží pečlivě na pořadí, kompletnost, duplicitu a kvalitu všech balíčků — soubor (například .doc dokument) se musí stáhnout v pořádku, jinak jej neotevřu. Spolehlivé protokoly řadí balíčky do správného pořadí a říkají si odesílateli o scházející balíčky, pročež jim jejich činnost trvá déle — každý spolehlivý protokol tedy musí umět odeslat požadavek ve smyslu „chybí mi balíček, pošli náhradní“, každý datový balíček posílaný přes bezpečný protokol musí mít v rámci zásilky své pořadové číslo.
Nejrozšířenější spolehlivý protokol jest TCP („transmission control protocol“ — protokol pro řízení přenosu). Jeho verze pro internet se pak nazývá TCP/IP.
Nespolehlivé protokoly
[editovat]Nespolehlivé protokoly neřadí balíčky, nekontrolují duplicitnost ani se nedotazují po balíčcích scházejících, nicméně zachovávají reálný čas. Využijeme je tedy, sledujeme-li přímý přenos nebo hovoříme-li s někým přes webkameru — zde jsme ochotni tolerovat, že nám sem tam na chviličku vypadne zvuk nebo zazrní obraz, vidím-li to, co se děje právě teď. Nejrozšířenější nespolehlivý protokol se jmenuje UDP (universal datagram protocol).
Komunikační port
[editovat]Oba druhy protokolů však potřebují umět přiřadit balíček konkrétnímu procesu. Od toho jsou zřízena „čísla portu“, takřečené komunikační (síťové) porty. Všechny datové balíčky putující sítí jsou zkrátka opatřeny nějakým číslem. Balíčky, které náleží ke stejnému „souboru“ (procesu), mají toto číslo vždy stejné. Často užívané kanály mívají již předem definovaná čísla portu, na kterém jim počítače „naslouchají“.
Wikipedie nás nezklame ani v případě transportní vrstvy počítačové sítě, protokolu TCP, TCP/IP nebo UDP nebo síťového portu.
Relační vrstva počítačové sítě
[editovat]Relační vrstva je pátou vrstvou počítačové sítě. Na úrovni relační vrstvy jde konečně o samotné uživatele sítě — už ne o procesy, které probíhají mezi počítači, ale o člověka. Na této vrstvě už se balíčky nepředávají podle toho, jakému procesu patří, ale podle toho, jakému patří uživateli. Zaměřujeme se zde především na identifikaci uživatele (ptáme se „Kdo to je?“ — užíváme uživatelská jména), na autentifikaci (ptáme se „Je to skutečně on?“ — užíváme bezpečnostní hesla) a soustředíme se na to, abychom to, co patří jednomu uživateli, předali skutečně pouze jemu — jde o relace.
Protokol užívaný na relační vrstvě se nazývá TELNET. Původně měl být k použití pro veškerou komunikaci na internetu, nicméně nebyl šifrován a tudíž adekvátně zabezpečen. Proto byl vyvinut protokol SSH („secure shell“, bezpečná příkazová řádka) — ten je již proti podloudným hackerům obrněn sofistikovaněji (je šifrován, lze jím ovládat počítač na dálku a podobně).
Pár článků o relační vrstvě počítačové sítě, heslu, TELNETu, SSH a podobných záležitostech.
Prezentační vrstva počítačové sítě
[editovat]Vymyslíme-li něco ohromně užitečného a zajímavého, musíme to rovněž umět na odpovídající úrovni odprezentovat, abychom pro naši věc nadchli i ostatní. Sebezajímavější nápad neobstojí bez dobré prezentace. I proto je zde prezentační vrstva počítačové sítě.
Úkolem prezentační vrstvy je převádět získané nuly a jedničky do formy, ve které jí porozumí jednotlivé aplikace; řeší, zda je daný soubor textem, zvukem, grafikou či něčím ještě docela jiným. Kromě rozpoznávání typů souborů, se kterými následně různě nakládá, má na starost ještě kódování znaků, jazyková nastavení a podobně. (Například zobrazují-li se nám na některých webových stránkách špatně písmena s diakritikou, je patrně chyba na úrovni prezentační vrstvy.)
Reprezentanty protokolů prezentační vrstvy jsou například SMB nebo MIME. Druhý jmenovaný mimo jiné rozeznává přílohy u e-mailů — některé obrázky zobrazí rovnou do textu, upozorní na možný vir a tak dále.
Hloubavé hlavy jistě čekají na články o prezentační vrstvě počítačové sítě a protokolech SMB a MIME, které pro ně připravila Wikipedie.
Aplikační vrstva počítačové sítě
[editovat]
Následuje aplikační vrstva počítačové vrstvy — ta již zaručuje plné uživatelské rozhraní. Spravuje síť i místní data, zajišťuje, aby se na webové stránce správně zobrazily obrázky i texty, dbá, aby různé věci nelezly přes sebe a podobně. Stará se o to, aby uživatelé mohli pohodlněji spravovat a přistupovat ke svým datům. Cíl aplikační vrstvy je, abychom mohli s daty, které jsou na síti (například na Internetu) zacházet stejně dobře, jako s daty, která máme uvnitř počítače.
Grafické uživatelské rozhraní následně zajišťuje jednoduché ovládání počítače — zpravidla prostřednictvím interaktivních grafických prvků; přináší nám ikony, tlačítka, posuvná ona a tak dále.
Nejrozšířenější komunikační protokol na Internetu jest protokol HTTP (hypertext transfer protocol) a HTTPS — oba dva jsou zde od toho, aby do našeho počítače správně přenášely webové stránky, abychom si je mohli zobrazit, jako kdyby byly u nás v počítači. Druhý jmenovaný je tentýž, jako první, jen je šifrovaný — užívá se na stránkách, kde jde o něco důležitého a kde se zadávají hesla. S první jmenovanou, nezabezpečenou verzí lze totiž hesla hackovat veskrze snadno (FBI sice heslo ukradne i protokolu HTTPS, ale ne tak snadno).

Na sofistikovanějších internetových úložištích se dále užívají protokoly FTP a FTPS; kdo si stahuje své e-maily do počítače (například prostřednictvím Thunderbirdu či podobné aplikace), ten zase pravděpodobně užívá protokol POP („post office protocol“). Mejly samotné zase bývají zpravidla odesílány skrz protokol SMTP („simple mail transfer protocol“).
Brány hlubšího studia otevírá Wikipedie — ví vše o aplikační vrstvě počítačové sítě, grafickém rozhraní, protokolech HTTP, HTTPS, FTP, FTPS i o FBI.
URL — uniform resource locator
[editovat]URL (tedy „jednotná adresa zdroje“) je skupina slov oddělovaných rozličnými interpunkčními znaménky. Slouží k přesné specifikaci toho, kde mají být na internetu nalezena požadovaná data — jde o normu. Má následující tvar:
protokol://uživatel:heslo@server:port/směrník?parametry#část
Protokolem je nejčastěji HTTP nebo HTTPS. Skrze vyhrazené místo pro uživatele a heslo se lze do stránky přihlásit přímo přes adresní řádek prohlížeče, ač se to nedoporučuje (například proto, že heslo zůstane vyditelné). Serverem se rozumí webová stránka, ze které informace stahujeme (tedy příkladně seznam.cz). Dále se soustředíme na číslo portu (protokol HTTP mívá portové číslo 80), na směrníky (podstránky, které nás posílají v rámci serveru, například „/aktuality.html“) a na parametry (na složitějších stránkách, například při generování map nebo editování Wikipedie, jejich udáním teprve spustíme program, který nám stránku vygeneruje). Poslední věcí, kterou můžeme skrze URL udat, jest část — odkaz totiž může vést rovnou k nějakému speciálnímu podnadpisu (třeba „#Programovatelnost“).

Části URL kódu, které zrovna udávat nechceme, jednoduše vynecháme — abychom se dostali na Seznam, stačí tudíž zapsat pouze „http://seznam.cz“. (Příkladem adresy, kde je užit jiný protokol, než HTTP, může zase být třeba adresa Prahů — „telnet://prahy.mmh.cz:3333“.)
URN — uniform resource name
[editovat]Dále známe i URN — jednotný identifikátor jména. Například prostřednictvím mezinárodního číslování knih určuje, z jaké knihy jsme citovali (isbn:80-253-0108?page=253 — Velký německo-český a česko-německý slovník, nakladatelství Fragment, strana dvoustá padesátá třetí), udává telefonní číslo (phone: +420 777777777) nebo mail (mailto: jan.novak@volny.cz).
Wikipedie si s URL, URN i URI pochopitelně ví rady.
Co nalezneme na Internetu?
[editovat]Na Internetu (nebo na „webu“, i když web je v tomto významu slova jen podmnožinou Internetu — například Prahy totiž jsou rovněž na Internetu, ačkoli nejsou žádnou webovou stránkou, e-maily lze odeslat rovněž bez webu a podobně) nalezneme spoustu zajímavých věcí.
Prvně vyhledávače a portály — skrze ně se dostáváme k rozličným dalším webům a dohledáváme si potřebné informace, ať už prostřednictvím Googlu (tedy ve své nejjednoduší podobě skutečně vyhledávače) nebo za pomoci Seznamu (tedy portálu — na úvodní stránce Seznamu totiž kromě vyhledávacího políčka najdeme i e-mail, noviny, předpověď počasí nebo horoskop).
Dále nám Internet nabízí rozličná shromaždište informací — to jsou například Wikipedie, You Tube, ČSFD, firemní a osobní stránky rozličných podnikatelů a podobně.
Na třetím místě rozlišujeme webová rozhraní newebových služeb — tím rozumíme záležitosti, které existují i ve skutečnosti mimo svět nul a jedniček a které se přes Internet pouze prezentují — tedy třeba elektronické zpravodajství, IDOS, e-shop, mapy.cz nebo e-bankingy.
Pak jsou jistě každému dobře známy komunikační prostředky — e-mail, Facebook, Skype či ICQ.
A když nám ani toto nestačí, můžeme ještě rozšířit možnosti vlastního počítače, například spustit internetovou hru, nechat si vypočítat příklad internetovou kalkulačkou nebo nahrát soubour na Ulož.to — můžeme si zkrátka dovolit vzdáleně spouštět programy a využívat zdroje, které by se nám do vlastního počítače tak dobře nevešly.
Jak psát e-mail
[editovat]E-mail jest jednou z nejzákladnějších věcí Internetu, používají jej veliké masy lidí. Ačkoli na první pohled může působit výrazně neformálněji, než rukou psaný či tištěný dopis, co putuje v obálce, mělo by i psaní e-mailů odpovídat alespoň elementárním pravidlům, aby elektronická komunikace měla nějakou úroveň.
Každý e-mail by měl mít:
- předmět (aby bylo jasné, oč jde — zejména u adresátů, kteří dostávají pošty velké množství, může rozhodovat o jeho přednostním přečtení, srozumitelně zvolený předmět může leckomu pomoci při vyhledávání zprávy v historii a podobně),
- oslovení (nějaký odpovídající pozdrav),
- stručné načtrtnutí, o co půjde (věta či dvě krátkého shrnutí, čemu se ve své zprávě chcete věnovat),
- tělo e-mailu (kde popíšete vše, co máte na srdci),
- adekvátní rozloučení a podpis.
Pozor bychom si měli dávat na přílohy. Píšeme-li nějaké osobě poprvé, je dobré to s přílohami nepřehánět, neb nemusíme vědět, jak to má s jejich zpracováním ve své schránce zařízeno. Velké soubory je obecně lepší ke zprávám nepřikládat, ale spíše je nahrát na vhodné internetové úložiště. Nanejvýš nepříjemné pak pochopitelně je zapomenout připojit přílohu, která se od vás očekává a kterou v těle e-mailu slibujete.
Každý e-mail má rovněž hlavičku, kterou si můžeme ve schránce nechat zobrazit. Stejně jako celý nám došlý e-mail je textovým souborem. Obsahuje informace o tom, od koho a komu je e-mail poslán, kdy byl odeslán, komu se má odpovídat, jaký má předmět, kdo je ještě v kopii a podobně. I v případě zdržení na síti (když se zpráva zpozdí) lze tudíž dohledat, zda jej dotyčný skutečně odeslal včas. Úpravami údajů v těchto hlavičkách se zabývají ti, kteří rozesílají spamy — lze je proto hůře identifikovat.
Jak udělat promítanou prezentaci
[editovat]K výrobě multimediální prezentace, kterou bychom následně rádi promítali, můžeme použít například programy „LibreOffice Impress“ nebo „Power Point“. Tyto dokumenty se neskládají ze stránek, nýbrž z jednotlivých snímků prezentace. V programech si můžeme nastavit různé rozličnosti, vyrobíme jednotlivé „slajdy“ s textem i obrázky, nastavíme přechody mezi snímky a podobně. Hotovou prezentaci lze dobře využít jako doplnění mluveného projevu.
Při tvorbě multimediální prezentaci bychom měli mít na paměti, že hlavní je mluvené slovo. Dále je dobré dávat pozor na správný kontrast, doprovázet prezentaci vhodnými obrázky a podobně. Zejména bychom se měli soustředit na to, že méně je někdy více.
Obsáhlejší pojednání o prezentacích pak zde.
Autorská práva
[editovat]
Chceme-li ve svém díle využít něco, co jsme sami nevytvořili, například ocitovat část cizí odborné práce, měli bychom uvést autora, knihu a tak podobně. Pokud přímo citujeme konkrétní věty či odstavce, obvykle je graficky odsadíme (dáme do uvozovek, napíšeme kurzívou, odsadíme do odstavce) a vzápětí uvedeme, kdo a z jaké knihy byl citován. Autora či svazek je však potřeba uvést, i když se některou prací jen inspirujeme — uvedeme, kde jsme sebrali odborné podklady. Na uvádění autorů je zavedeno mnoho zvyklostí i pravopisných úzů.
Výjimkou jsou texty publikované pod licencí Creative Commons, platné například na Wikipedii — ta texty uvolňuje pod svobodnějšími pravidly, dovoluje ho sdílet i upravovat, ač zachovává povinnost uvést autora. Autor naproti tomu už nemůže měnit podmínky, pod kterými dílo uložil. Volně lze rovněž šířit díla, jejichž autor je už velmi dlouho po smrti (to je pak takzvané veřejné vlastnictví).
Obtížnější je to zpravidla s multimediálními záležitostmi, obrázky či videy — autor může zakazovat šíření či jej zpoplatnit, ze dne na den své podmínky měnit a podobně. To se týká například i rozličných stahovatelných programů.
Licencí, pod kterými lze svoje dílo uvolnit (nebo vlastně neuvolnit) existuje vícero — pojmenovává je a vztahy mezi nimi popisuje schéma výše. Licence jsou rozličné, od volně stahovatelných po privátní, proprietární softvery — výše jsou vyznačeny i přechodné možnosti mezi nimi.
Tradiční odkazy: Autorská právo, Creative Commons, Copyleft, Freeware, open source a podobně.
Zabezpečení na Internetu
[editovat]Webové stránky mají ve zvyku člověka sledovat; na úrovni relační vrstvy webové stránky zjišťují, ze které stránky uživatel přišel a na jakou zase odchází. Některé organizace se tomuto sledování snaží zamezit, jelikož jej nepovažují za správné. Například máme-li ve Firefoxu aktivovanou funkci Do Not Track, webové stránky dostanou přinejmenším zprávu o tom, že si nepřejeme být sledováni. Sledování také částečně unikneme, pokud si otevřeme anonymní prohlížení. Úplně však tomu, aby o nás webové stránky zjišťovaly, kudy vedou naše cesty internetem, neunikneme nikdy.
Dalším fenoménem jsou takzvané soubory Cookies. Jde o maličké textové soubory (obvykle několik bitů), které textové stránky ukládají do paměti našeho prohlížeče — při každé další návštěvě je pak prohlíží, edituje nebo přidává nové. Jsou to maličké „kousíčky“, které si u nás stránky odkládají a příště je znovu zkoumají.
Dobré jsou například k tomu, že webové stránky rozpoznají, že jsme někam přihlášeni. Jsme-li například zrovna přihlášeni k Seznamu, jako k registrovanému uživateli se k nám chovají i Mapy.cz a podobně — k tomu ostatně byly vymyšleny.
Nevýhodou cookies zas bezesporu je, že opět napomáhají k našemu sledování — skrz informace průběžně ukládané do těchto textových souborů lze velmi dobře zjistit, kudy vedly naše cesty internetem, na co jsme kde klikli a podobně.
Chcete-li se s nákladem sušenek ve svém prohlížeči podívat ještě někam jinam, přečtěte si něco o cookie na Wikipedii.